Part of Content release process
Appendix E - Deployment models
Depending upon the scale and use cases of the organisation deploying a terminology solution, different components may be required.
Typically these decisions revolve around requirements relating to:
- content authoring
- control of the content authoring process
- control of the release/publication process
- production runtime use of published content
Main choices
You will need to make a number of decisions which will be based on the use cases for the deployment. These sections explain the main decisions shown in each of the deployment configurations.
Ontoserver instances
Ontoserver can operate as both a read/write FHIR terminology authoring server, and as a read-only terminology query server. Depending upon the size of the organisation and the split of these two activities, one or more Ontoserver instances may be a good choice.
Typically with resource level security and community authorisation server features, only one read/write authoring terminology server is necessary for an organisation.
For organisations only using terminology and not authoring, a read/write authoring terminology server may not be necessary, and one or more read-only instances may be needed.
For organisations with content authoring needs and a desire for strong control and separation between authoring and production use of terminology, multiple Ontoserver instances can be used to separate the authoring from the use functions. A staging terminology server can be added to test out deployments of content in a production-like environment before publishing the content on a production endpoint for downstream use.
Authorisation
Some organisations may choose to use an Ontoserver instance on an internal secured network and not require a complex authorisation model. For organisations that need to provide more open endpoints and, or need to apply nuanced levels of access, an authorisation server will be required. The role of an authorisation server is to issue bearer tokens which Ontoserver can inspect to determine whether the bearer of that token is authorised to perform the operation requested.
These tokens can be issued by any server capable of creating the right embedded claims matching the desired authorisations for Ontoserver, however configuring and achieving this this can be a challenge. It is also possible that the directory used to identify users for an organisation which can perhaps issue tokens, cannot be freely enough to manage the authorisations desired for Ontoserver.
For that reason Ontocloak, an enhanced version of Keycloak, has been created to operate as an authorisation server in a solution deployment. While it can manage identities and authentication for uses, it is intended to be used with Open ID Connect or SAML identity providers an organisation already has to achieve identity and authentication.
Ontocloak provides the ability to then configure for those identities the appropriate level of access to Ontoserver and, or Atomio endpoints, and enables the SMART on FHIR authorisation flow for Snapper, Shrimp and OntoCommand clients (and other SMART on FHIR clients).
Ontocloak can also be configured to integrate with an external SAML or OpenID Connect identity provider, or to federate identities from a Kerberos or Active Directory/LDAP source. If authorisation is required in the solution, use of Ontocloak is recommended as it simplifies configuration.
Syndication server
A syndication server is a useful addition to a deployment when the organisation:
- creates binary indexes for SNOMED CT and/or LOINC
- wishes to stage content from internal or external sources other than in an authoring server where active editing is done
- wishes to have recorded release history from production publications, or
- is using ephemeral production read-only instances which require a static source of truth to rebuild from
Atomio is a component designed for this purpose. It can host multiple Atom syndication feeds and associated artefacts which Ontoserver can read, and has an API to manipulate the feed and entry content.
Deployment configurations
The following sections describe a series of deployment configurations to illustrate the key decisions and trade-offs. These options all assume the use of an authorisation server (either Ontocloak or otherwise) to control access level to resources by various different roles.
Choosing between these models is a trade-off between control/functionality and complexity/cost of the deployment.
Single read or write terminology server
This is the simplest option, where content is authored and used from the same single read/write terminology server endpoint.
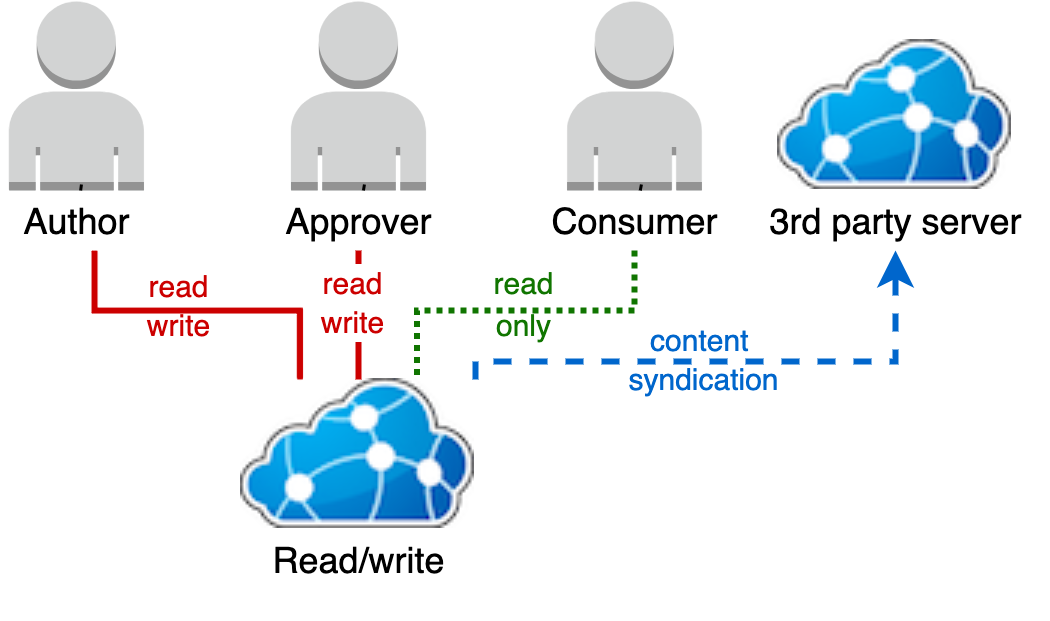
In this model Authors can read and write content, and Consumers can read the author's content at any time. If Authors and/or Approvers wish to exert some control over when Consumers can see certain content, this can be achieved by associating Consumers with a community which is given read-only access upon content approval, more information in the Community Management training. However, further separation between approved and "under development" content requires a separate production endpoint.
Approvers still have control over the content included in the syndication feed through the procedure Approving FHIR Resources for publication in the authoring server, however this does not affect access through the FHIR API.
Separate production endpoint
Separating out a production endpoint allows control over when content under development is exposed to consumers. It also allows different infrastructure for performance and availability to be used for content development versus content use.
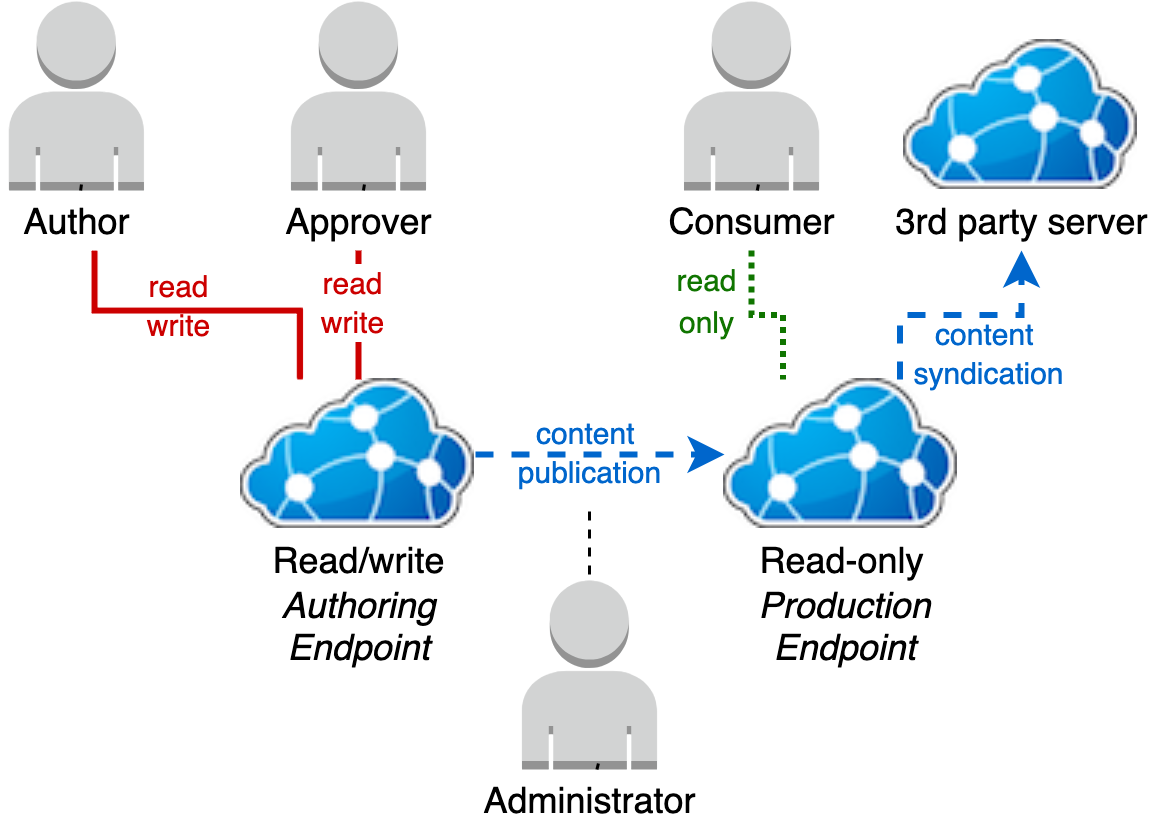
Under this model, the content development/publication process is:
- Authors can develop content on an Authoring terminology server.
- When a piece of content is completed, it can be approved by an Approver.
- When the approved content state of the Authoring terminology server represents a cohesive publishable state, an Administrator can update the production terminology endpoint. This essentially synchronises the Production server's state to match the approved content state in the Authoring server represented by its active syndication content.
Approved content changes can be released using this procedure as often as desired. An authoring server can be used to collect up a milestone set of changes to be released.
Alternatively, this model can be used for a continuous delivery style model, where the read-only endpoint can be configured to pull new content from the read/write server's syndication endpoint on a schedule - refer to the preload section in Configure Ontoserver.
Syndication server and separate production endpoint with staging endpoint
The most comprehensive solution is to use both a Staging server and a syndication server. This allow for full release history, rollbacks to any previous release point and production-like testing of release candidates prior to production publication.
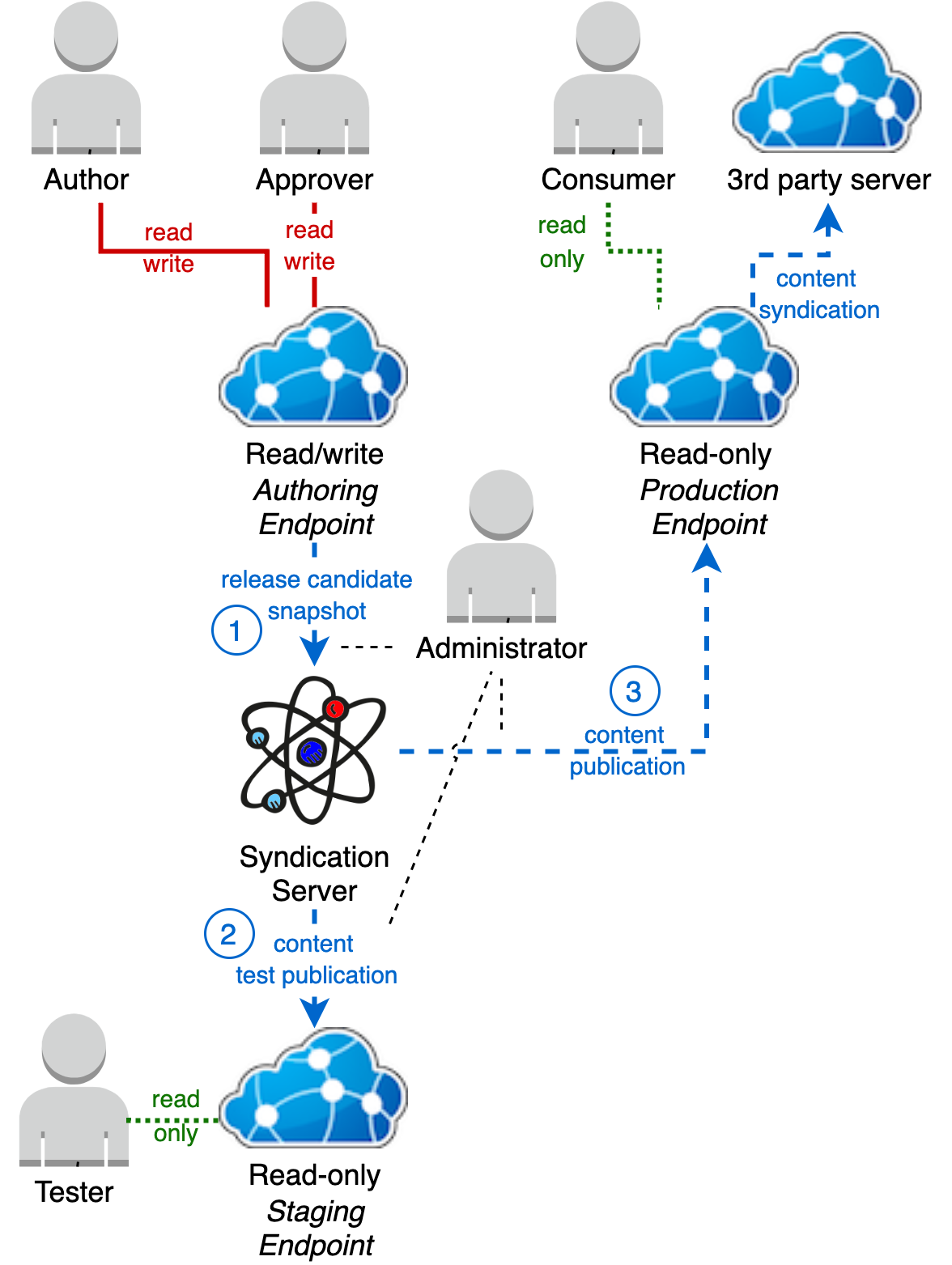
Under this model, the content development/publication process is:
- Authors can develop content on an Authoring terminology server.
- When a piece of content is completed, it can be approved by an approver.
- When the approved content state of the authoring terminology server represents a cohesive publishable state, an Administrator can create a "release candidate" snapshot from the authoring server's syndication state.
- An administrator can then deploy that release candidate to the staging server.
- Manual and/or automated testing can be performed against the staging server. If testing fails changes changes will be required on the Authoring server and the process returns to step 1 above.
- Once testing has passed on the Staging server, an Administrator can update the production terminology endpoint. This essentially synchronises the production server's state to match the tested and approved release candidate snapshot. Rollback is achieved by configuring a historical release candidate snapshot.
Last edited: 3 March 2021 3:35 pm