Accessing HES with DAE
Guidance on accessing Hospital Episode Statistics (HES) data using the Data Access Environment (DAE).
Introduction
This guide is intended to help users accessing Hospital Episode Statistics (HES) data when using Databricks in DAE. It provides guidance on:
- working with SQL queries
- useful HES examples
Please refer to the section Useful links for further information on HES.
The Using Databricks in DAE guide will help you get up and running using Databricks. It provides guidance on:
- logging in to Databricks
- creating and using notebooks and clusers
- working collaboratively using shared folders and shared databases
Contact us
If you have any questions about guidance or functionality, or are experiencing any operational issues, such as problems with system access, please contact our National Service Desk on 0300 303 5035 or via email at [email protected].
For general enquiries, such as questions about Data Sharing Agreements (DSAs) or other data-related issues, please email our contact centre at [email protected].
Working with SQL queries
Writing a query
Databricks uses notebooks and cells to run queries. A notebook allows you to write and execute code, a section at a time, using cells. Please refer to Using Databricks in DAE for further information.
Running a query
To run your query:
- Click the triangle on the right of the cell and select Run Cell from the drop-down list.
- Alternatively, you can press SHIFT + Enter within the cell.
Your results will be displayed below the cell.
To run multiple cells within a notebook:
- Click Run All from the top of the notebook.
The results will be displayed below each cell.
Format and layout
Case and indentation are not important but being consistent can make the query easier to read. However, where a user is filtering against the data the filter will be case sensitive. For example, when looking at diagnosis ‘f50’ is not the same as ‘F50’ due to the difference in letter case and may not return any results.
The following colours are assigned by the Databricks interface and help with readability:

SELECT t1.fyear,
CASE WHEN t1.startage_calc between 0 and 17 THEN 'Under 18'
WHEN t1.startage_calc between 18 and 120 THEN '18 and over'
ELSE 'Unknown'
END AS age_group,
SUM(t1.fae)
FROM hes.hes_apc_10y t1
WHERE t1.fyear IN ('1617','1718')
AND t1.fae = 1
GROUP BY t1.fyear,
CASE WHEN t1.startage_calc between 0 and 17 THEN 'Under 18'
WHEN t1.startage_calc between 18 and 120 THEN '18 and over'
ELSE 'Unknown'
END;
;
Analysing HES - Examples
Below are some example pieces of analysis to help you get started working with queries using HES data.
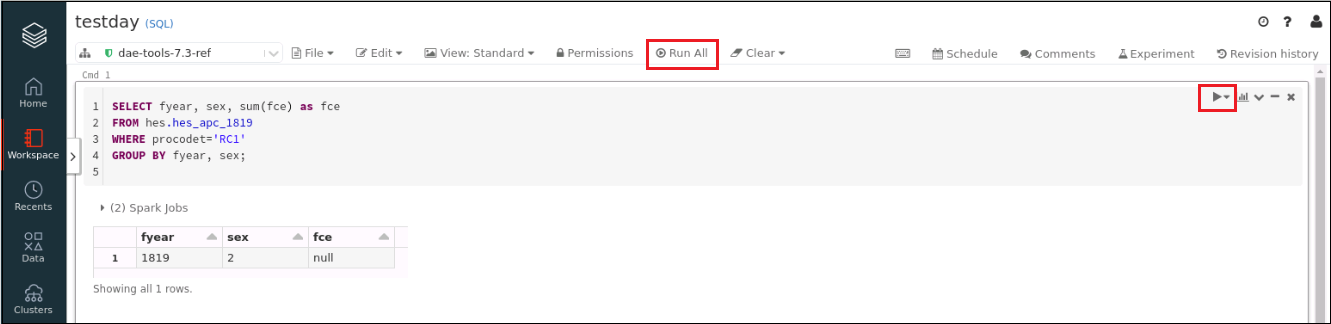
Find the number of Finished Consultant Episodes (FCEs) by gender
The following query will allow you to find the number of Finished Consultant Episodes (FCEs), by gender, in 2018/19 for a trust (such as RC1):
SELECT fyear, sex, sum(fce) as fce
FROM hes.hes_apc_1819
WHERE procodet=’RC1’
GROUP BY fyear, sex;
How many children/adults were admitted to hospital with a suspected eating disorder?
It is not possible to identify suspected eating disorders. However, it is possible to identify the number of Finished Admission Episodes (FAE) with the ICD-10 code F50, which is a primary diagnosis of an eating disorder.
The following query uses the icd10_codes table as a lookup to return the description. Note that the icd10_codes table is held in the dss_corporate database rather than the HES database.
SELECT t1.fyear,
t1.diag_3_01,
t2.full_description,
CASE WHEN t1.startage_calc between 0 and 17 THEN 'Under 18'
WHEN t1.startage_calc between 18 and 120 THEN '18 and over'
ELSE 'Unknown'
END AS age_group,
SUM(t1.fae)
FROM hes.hes_apc_10y t1
LEFT OUTER JOIN dss_corporate.icd10_codes t2 ON t1.diag_3_01=t2.code
AND t2.version='5th ed'
WHERE t1.fyear IN ('1617','1718')
AND t1.diag_3_01='F50'
AND t1.fae=1
GROUP BY t1.fyear,
t1.diag_3_01,
t2.full_description,
CASE WHEN t1.startage_calc between 0 and 17 THEN 'Under 18'
WHEN t1.startage_calc between 18 and 120 THEN '18 and over'
ELSE 'Unknown'
END;
;
Most queries begin with a SELECT command. You may also occasionally see queries using the CREATE or DROP command. Note that CREATE and DROP operations can only be run in your own database.
The FROM command instructs the query which database and table to use. In this case the first table is hes.hes_apc_10y and immediately after this there is t1. This is known as a table alias, which is used to help make the query easier to read. Instead of writing hes.hes_apc.fyear each time you wish to refer to the fyear column, you can just write t1.fyear and the system knows that t1 is the same as hes.hes_apc_10y.
You can use any alias you like, but we advise using short names so they are easier to read for larger queries. For example, t_data or t_d_ref (for a diagnosis reference).
Under the FROM command there is a LEFT OUTER JOIN command that tells the query to join to the next table, which is the icd10_codes lookup. LEFT means that all the values on the left-hand side (the first table) will be returned even if there isn’t a match in the right table. This is good practice particularly with reference tables where a null or bad value in your data might otherwise be excluded, giving you incorrect results. If you want to use the reference table as a filter then just specify the JOIN command.
The join in ON t1.diag_3_01=t2.code is where the value in the t1 hes.hes_apc_10y three-character diagnosis field is equal to the code in the t2 diagnosis lookup table. The same applies to AND t2.version=’5th ed’. Some of the reference tables contain more than one code version, such as the icd10 codes table which contains versions ‘2000’,’4th ed’ and ‘5th ed’. The version most appropriate to the year of the data should be used. Enclosing the value single a quotation mark will specify the value as text in the query.
The SELECT command is a specification of columns required in the results output. Each one is separated by a comma, except for the final column. The first two columns specified are fyear (financial year) shown as two digits, 1617 for April 2016-March 2017 and diag_3_01 which is the first 3 digits of the first coded diagnosis, the reason for admission. The full description is selected from the reference table.
The CASE command allows the startage_calc (the age at the start of the episode) to be reported as a value for ‘Under 18’ and ’18 and over’ in the results table.
At the end of the CASE there must always an END command. In this query there is also an optional AS age_group, which specifies age_group as a column alias for the whole CASE statement in the same way that t1 is a table alias.
Under the SELECT command there is the aggregate function SUM(t1.fae). FAE (Finished Admission Episodes) contains the value 1 if the finished consultant episode is the admitting episode and 0 for any other record. This will only add up admissions in the year.
The WHERE command is used to filter the data. If this is not present all the data will be returned in the results table. In this query fyear has been limited to 1617 and 1718 financial years using the IN command. The values are in single quotes so they behave as text, e.g. 2001/02 would be ‘0102’. The first diagnosis is equal to F50 and the only records looked at are ‘finished admission episodes’ where fae=1.
A GROUP BY command is only required when using an aggregate function in your select statement such as SUM(), COUNT() or AVG(). This tells the query which columns the sum should apply to which is usually all the non-aggregate columns in the data. The CASE statement is the same as the one in the SELECT command but it does not have the AS column alias at the end.
You can order the results by the column name age_group but you can’t group by age_group. This is because the variables in the SELECT statement haven’t yet been created, so those new variables cannot be used. The whole GROUP BY statement is required to perform the sum function and finish creating the columns with their new names.
How many fracture admissions by age band and area fractured
The following query counts admissions that have a fracture diagnosis on the admission episode, by year, age band and fractured body area.
The query shows how to create columns, in your results table, based on data in the table HES_APC_10Y.
SELECT FYEAR,
CASE WHEN STARTAGE_CALC BETWEEN 0 AND 9 THEN '0_9'
WHEN STARTAGE_CALC BETWEEN 10 AND 19 THEN '10_19'
WHEN STARTAGE_CALC BETWEEN 20 AND 29 THEN '20_29'
WHEN STARTAGE_CALC BETWEEN 30 AND 39 THEN '30_39'
WHEN STARTAGE_CALC BETWEEN 40 AND 49 THEN '40_49'
WHEN STARTAGE_CALC BETWEEN 50 AND 59 THEN '50_59'
WHEN STARTAGE_CALC BETWEEN 60 AND 69 THEN '60_69'
WHEN STARTAGE_CALC BETWEEN 70 AND 79 THEN '70_79'
WHEN STARTAGE_CALC BETWEEN 80 AND 120 THEN '80+'
ELSE 'Unknown' END AS AGE_BAND,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S02')>0 THEN FAE ELSE 0 END) AS SKULL,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S12')>0 THEN FAE ELSE 0 END) AS NECK,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S22')>0 THEN FAE ELSE 0 END) AS RIB,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S32')>0 THEN FAE ELSE 0 END) AS SPINE_PELVIS,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S42')>0 THEN FAE ELSE 0 END) AS SHOULDER,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S52')>0 THEN FAE ELSE 0 END) AS FOREARM,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S62')>0 THEN FAE ELSE 0 END) AS WRIST,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S72')>0 THEN FAE ELSE 0 END) AS FEMUR,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S82')>0 THEN FAE ELSE 0 END) AS LOWER_LEG,
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S92')>0 THEN FAE ELSE 0 END) AS FOOT
FROM HES.HES_APC_10Y
WHERE FYEAR IN ('1112','1213','1314','1415','1516','1617','1718','1819')
GROUP BY CASE WHEN STARTAGE_CALC BETWEEN 0 AND 9 THEN '0_9'
WHEN STARTAGE_CALC BETWEEN 10 AND 19 THEN '10_19'
WHEN STARTAGE_CALC BETWEEN 20 AND 29 THEN '20_29'
WHEN STARTAGE_CALC BETWEEN 30 AND 39 THEN '30_39'
WHEN STARTAGE_CALC BETWEEN 40 AND 49 THEN '40_49'
WHEN STARTAGE_CALC BETWEEN 50 AND 59 THEN '50_59'
WHEN STARTAGE_CALC BETWEEN 60 AND 69 THEN '60_69'
WHEN STARTAGE_CALC BETWEEN 70 AND 79 THEN '70_79'
WHEN STARTAGE_CALC BETWEEN 80 AND 120 THEN '80+'
ELSE 'Unknown' END,
FYEAR
ORDER BY FYEAR, AGE_BAND
The query starts with the SELECT command and creates a column called FYEAR (financial year) in the results table. An ‘age band’ column is then created using the CASE statement.
WHEN STARTAGE_CALC BETWEEN 0 AND 9 THEN '0_9'
The query line above calculates and returns a value when the HES calculated age is between the age band 0 and 9. A value is returned for each age band.
The END command denotes the end of the case statement and the AS command gives the query a name for the new column, in this case AGE_BAND.
A column is added to the results table which is a count of ‘first admission episodes’, (the episode that started the patient’s stay) for each body area.
SUM(CASE WHEN INSTR(DIAG_3_CONCAT,'S02')>0 THEN FAE ELSE 0 END) AS SKULL,
The query line above states that when the ICD10 code value S02 can be found in the diag_3_concat field, count the FAE (Finished Admission Episodes) field (which is 1 for FAE and 0 for other records, or if S02 isn’t in the diagnosis for that record count 0). This will result in a sum of all the FAE records that have S02 coded in any position.
In this query, if the patient has multiple fractures, such as a skull fracture and a rib fracture, they will be counted once for each body area.
This query is run against the HES_APC_10Y table which provides a ten-year view of data.
WHERE FYEAR IN ('1112','1213','1314','1415','1516','1617','1718','1819')
The query line above is used to filter the queries within the required years (April 2011 to March 2019) and means that multiple years do not need to be added together.
The columns with the SUM( are aggregate columns. When an aggregate function is used, the GROUP BY command must be used with details of the columns that are being aggregated against.
Note that the alias AS AGE_BAND is not used in the group by statement in this query.
The ORDER BY command is used to sort the results. As this command is used at the end of the query it is possible to refer to the AGE_BAND column by the alias rather than having to repeat the case statements.
How many patients between 5 and 25 had 10 or more outpatient attendances in any single 30-day period
The example query below shows how to join a table to itself and how to use Common Table Expressions (CTE) to manage subqueries that might be referenced more than once.
This is a more ‘advanced’ example for experienced SQL users.
WITH SETX AS
(SELECT T1.PSEUDO_HESID,
T1.PROCODE5,
T1.ATTENDKEY,
T2.ATTENDKEY AS ATTENDKEY2,
T1.APPTDATE,
T2.APPTDATE AS APPTDATE2,
T1.APPTAGE_CALC,
DATEDIFF(T2.APPTDATE,T1.APPTDATE) AS ATTGAP
FROM HES.HES_OP_1819 T1
INNER JOIN HES.HES_OP_1819 T2
ON (T1.PSEUDO_HESID=T2.PSEUDO_HESID
AND T1.PROCODE5=T2.PROCODE5)
WHERE DATEDIFF(T2.APPTDATE,T1.APPTDATE) BETWEEN 0 AND 30
AND T1.APPTAGE_CALC BETWEEN 5 AND 25
AND T2.APPTAGE_CALC BETWEEN 5 AND 26),
SETY
AS (SELECT PSEUDO_HESID,
PROCODE5,
ATTENDKEY,
APPTDATE,
COUNT(1)
FROM SETX
GROUP BY PSEUDO_HESID,
PROCODE5,
ATTENDKEY,
APPTDATE
HAVING COUNT(1)>9)
SELECT SETX.PROCODE5,
CASE WHEN APPTAGE_CALC BETWEEN 5 AND 15 THEN '5-15'
WHEN APPTAGE_CALC BETWEEN 16 AND 18 THEN '16-18'
WHEN APPTAGE_CALC BETWEEN 19 AND 25 THEN '19-25'
END AS AGE_BAND,
COUNT(DISTINCT SETX.ATTENDKEY2) AS ATTENDANCES,
COUNT(DISTINCT SETX.PSEUDO_HESID) AS PATIENTS
FROM SETX
WHERE SETX.ATTENDKEY IN (SELECT DISTINCT SETY.ATTENDKEY FROM SETY)
GROUP BY SETX.PROCODE5,
CASE WHEN APPTAGE_CALC BETWEEN 5 AND 15 THEN '5-15'
WHEN APPTAGE_CALC BETWEEN 16 AND 18 THEN '16-18'
WHEN APPTAGE_CALC BETWEEN 19 AND 25 THEN '19-25'
END
The WITH prefix tells the SQL that you are going to use a CTE. Please refer to Common Table Expression for further information.
This is followed by an alias name, an AS command and a query in brackets. If you use a second CTE you must put a comma after the first query.
In this example, the first query creates a CTE (an inline view or virtual table), called SETX, of all the records in the table where the same patient has a subsequent appointment within 30 days at the same provider.
The HES_OP_1819 table is given the alias T1 and is then joined to itself using a different alias T2. The table is joined on PSEUDO_HESID and PROCODE5 so all the attendances, for the same person, will be joined in both tables. For this analysis, a record is joined to itself, but this can be avoided by adding the filter where T1.ATTENDKEY<>T2.ATTENDKEY.
The query creates a new column using DATEDIFF which returns the number of days between the second attendance and the first. It is also used as a filter to only return records where the second attendance is 0 to 30 days after the first.
The query also checks age, using 25 as the maximum age in the first table but 26 in the second table in case the patient has had a birthday in the meantime.
Using this first query, the second CTE, SETY returns all the records from the first query where an attendance identified by PSEUDO_HESID, PROCODE5, ATTENDKEY and ATTENDDATE has joined to more than 9 different subsequent attendances, i.e. in relation to the question ‘where the patient has had 10 or more outpatient attendances in any 30-day period’.
The query returns a count of all the return attendances (note that the ATTENDKEY is ATTENDKEY2, the second attendance) and patients from SETX where the first attendance is one of those in SETY.
Useful links
Last edited: 28 July 2022 5:31 pm